As any data practitioner knows, data transformation can be messy and quickly become inefficient and difficult to scale. While there are straightforward optimization techniques that can be used to help alleviate costs of data transformation in Snowflake, getting more granular with how you think about your data workloads can provide an additional layer of cost optimization.
Some of the considerations in this article are not necessarily pure technical optimizations, but rather evaluations of how you can logically configure Snowflake to best serve your business at the lowest cost. For more technical optimizations, I’ll be using Coalesce, a data transformation solution built exclusively for Snowflake, to help demonstrate the techniques we’ll be discussing
Reduce warehouse bloat
Creating a virtual warehouse in Snowflake is incredibly simple. So simple, in fact, that users often end up with a plethora of virtual warehouses—which in turn creates compute inefficiency.
It’s not uncommon for a Snowflake admin to create a virtual warehouse for a specific initiative, department, and sometimes even for an individual user or use case. Since virtual warehouses in Snowflake run for a minimum of 60 seconds, this can result in idle time that could have been used elsewhere, whether by another process or user.
To avoid this idle time, consider creating virtual warehouses for specific processes or workloads, rather than creating them for logical units of the business. For example, instead of designating virtual warehouses for your data analysts, separated by the department they are in, consider creating one singular virtual warehouse that all analysts use. This allows it to be significantly more utilized and reduces the amount of idle time.
Evaluate your queue and scheduling tolerance
While consolidating your virtual warehouses can optimize your Snowflake consumption, it comes with a potential trade off: queuing. Queuing can be incredibly advantageous because you are optimizing the utilization of a warehouse. But, it is important to understand your workload and stakeholder tolerance for queuing before making changes to a virtual warehouse. If there is a tolerance for queuing, this can help optimize your Snowflake consumption.
Think about it like this: instead of having a Medium warehouse run your workloads in 10 minutes with no queuing, consider decreasing the size of the warehouse to a Small, where your workloads may queue temporarily and run in 15 minutes. It goes without saying that egregious queuing times can cause your bill to increase, but by evaluating the possibility of decreasing a warehouse size and tolerating a small queue, you are fully optimizing your warehouse in a smaller size.
| Standard Virtual Warehouse | |||
| Size | Credits per hour | Run Time | Total Credits Cost |
| S | 2 | 15 Minutes | 0.50 |
| M | 4 | 10 Minutes | 0.67 |
Determining the optimal schedule on which your workloads need to run can also help dramatically alleviate queuing. If you are currently running your entire data pipeline on the same schedule, evaluate the portions of the pipeline that don’t need to run as frequently.
For example, let’s assume a data pipeline processes both order and marketing data in the same workload. It is unlikely that the marketing data needs to be run more than once a day, but the order data is likely a higher priority as it impacts stakeholders and should be processed every hour. By rolling the marketing data over to a daily run cadence, you would only be processing that data when it is needed, thus optimizing your compute. This is true especially if the objects being built with the marketing data are full table truncations each run (an incremental processing strategy could also help with this). And if you use a data transformation solution like Coalesce, you can easily group the nodes in your data pipeline into jobs that can be run at different intervals.
| Standard Virtual Warehouse | ||||
| Size | Credits per hour | Run Time | Run Frequency | Total Credits Cost |
| S | 2 | 15 Minutes | Every Hour | 12 |
| S | 2 | 15 Minutes | Once a Day | 0.50 |
Column clustering
Column clustering is a technique that takes advantage of how Snowflake scans your data when executing a query. Behind the scenes, Snowflake stores data using micro-partitions. These micro-partitions store compressed data in small units, somewhere between 50 MB and 500 MB. These micro-partitions organize your data in a columnar format, and create groupings of rows in your table that map to specific individual micro-partitions.
Micro-partitions are derived automatically and, because of the small size of each partition, allow for extremely efficient querying (we’ll talk about this more in the next section). Snowflake will automatically cluster your data behind the scenes in the most efficient way, but as tables get larger or consistent query patterns emerge, it can be advantageous to implement a manual clustering key.
Snowflake defines its clustering keys as “a subset of columns in a table (or expressions on a table) that are explicitly designated to co-locate the data in the table in the same micro-partitions.” As tables continue to scale to larger and larger sizes, the query performance of those tables becomes increasingly important. By creating a clustering key, we can manually tell Snowflake to reorganize and store “like” data in the same micro-partitions. This allows for much faster query speeds as Snowflake only needs to scan the micro-partitions where it already knows the data exist.
However, setting a manual clustering key can be an expensive task as you are reorganizing the stored data and are burning Snowflake credits to do so. In order to maximize the value of using clustering keys, Snowflake recommends that the ideal candidate for column clustering meet all of the following criteria:
- The table contains a large number of micro-partitions. Typically, this means that the table contains multiple terabytes (TB) of data.
- The queries can take advantage of clustering. Typically, this means that one or both of the following are true:
- The queries are selective. In other words, the queries need to read only a small percentage of rows (and thus usually a small percentage of micro-partitions) in the table.
- The queries sort the data. (For example, the query contains an ORDER BY clause on the table.)
- A high percentage of the queries can benefit from the same clustering key(s). In other words, many/most queries select on, or sort on, the same few column(s).
Column clustering can dramatically help improve query performance and reduce costs, but if clustering is not a cost-effective option, you should still consider writing queries and data transformations that take advantage of our final technique, query pruning.
WHERE are you?
We’ve just discussed how defining a clustering key can help decrease your query times and optimize your Snowflake compute. The real magic of why this works so well has to do with Snowflake query pruning. Every time Snowflake executes a query, it attempts to prune the query to reduce the number of micro-partitions that it scans. Pruning is made possible by setting a filter in a WHERE or JOIN clause.
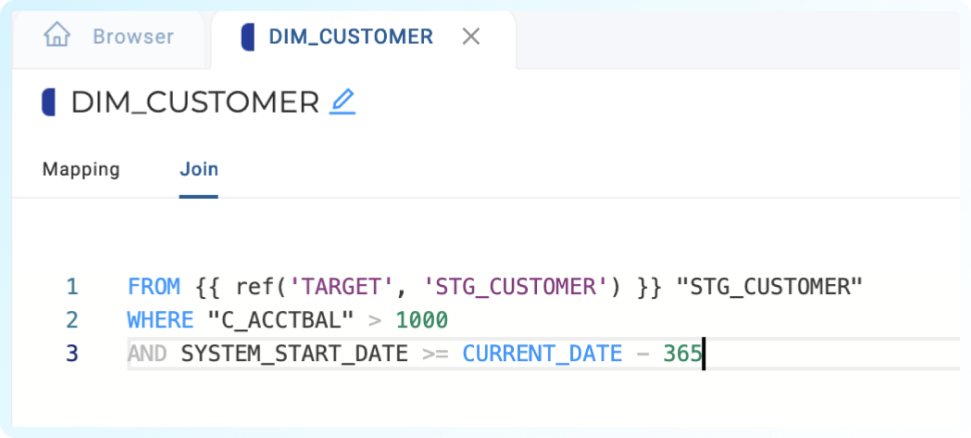
Snowflake is aware of what order the micro-partitions are stored in and the minimum and maximum values stored in each micro-partition. When equipped with a filter, Snowflake can execute a query and only scan the relevant micro-partitions related to your filter, to provide much faster query speed by ignoring all of the other micro-partitions stored in the table. This means that transformations should take advantage of query pruning when possible by including a filter.
While Snowflake micro-partitions data automatically, by taking advantage of both query pruning and clustering keys, you can significantly enhance the performance of your workloads and optimize your Snowflake consumption.
Prioritizing best practices
By thinking strategically about how Snowflake can best serve your business, you can optimize your usage using the practices discussed here and build sustainable and scalable data transformations. Additionally, using a data transformation solution like Coalesce allows you to implement any technique seamlessly and without having to write hundreds of lines of code, which can help you further optimize your Snowflake consumption and increase your data team’s ROI.
Want to give Coalesce a try? Create a free Coalesce account here, or request a demo.