Sasha Lionheart wrote a great blog on using Dynamic Tables to create Type 1 and Type 2 Slowly Changing Dimensions. Check out the article if you want to learn more about Dynamic Tables and Slowly Changing Dimensions.
There have been other blogs about using Snowflake Dynamic Tables with Coalesce.io. I wanted to see how this would work in Coalesce using our Dynamic Table Stage user defined node. You can learn more about this node type by viewing this Snowflake Quickstart.
I’m also going to show how the process can be automated even more by customizing the existing node and creating a Dynamic Table Dimension node.
To start I created the table that Sasha used by running the following SQL statements in the schema RANDOM_TESTING_DEV.PSA.
Next, I added this as a source in a Coalesce Workspace.
Standard Dynamic Table Stage
Customer History Dimension
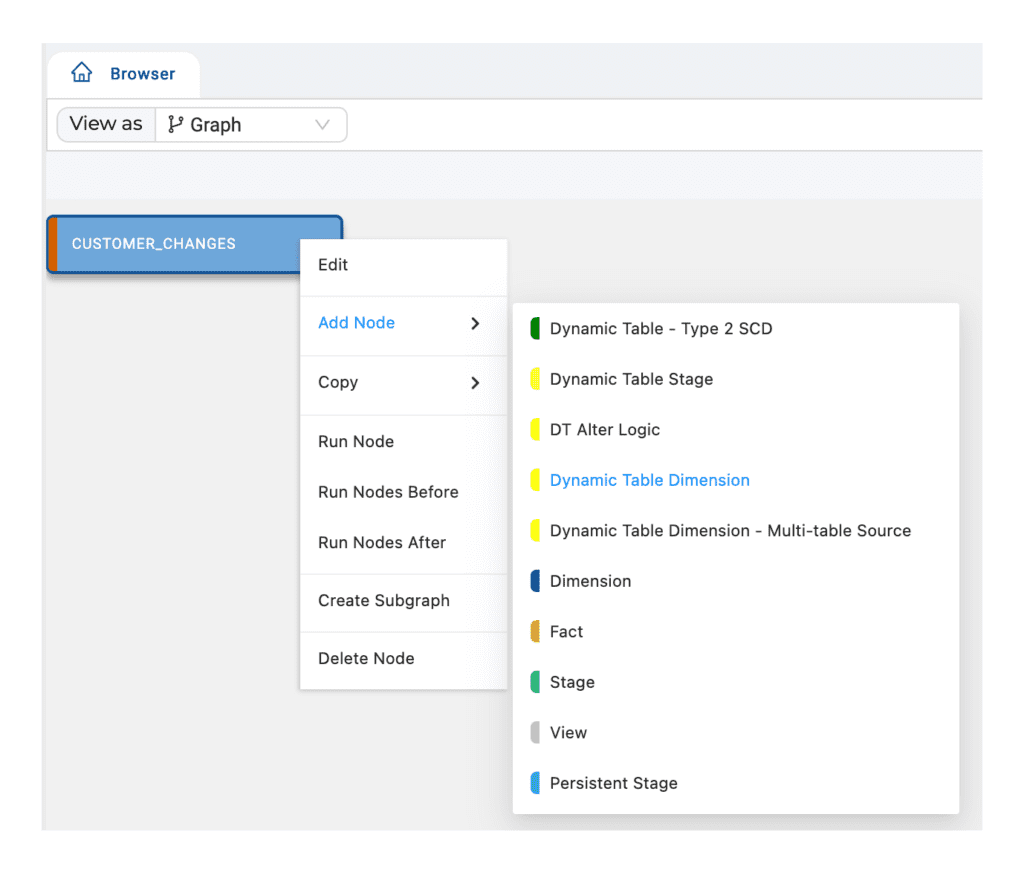
Next, I added Dynamic Table Stage node to my workspace:
After adding you’ll see a linked node prefixed with DT_:
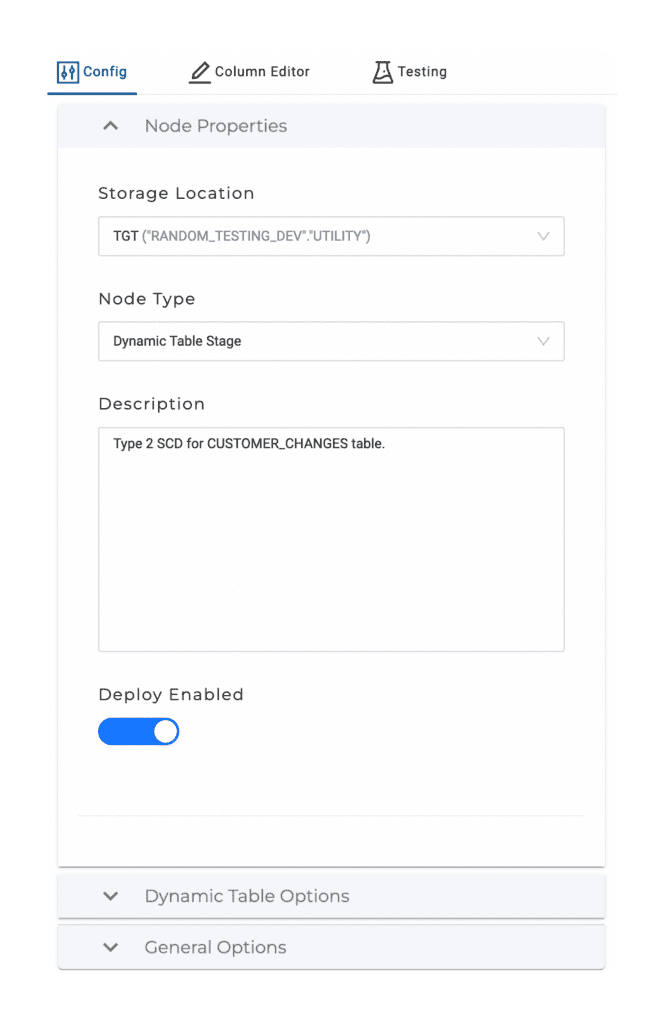
The node requires some configurations to be entered.
First are some Node Properties:
Storage Location: Where the Dynamic Table will be created.
Node Type: We are using the Dynamic Table Stage node.
Description: Text that will be added as a comment to the Dynamic Table.
Deploy Enabled: Sets whether or not the node should be part of a deployment to a higher-level environment.
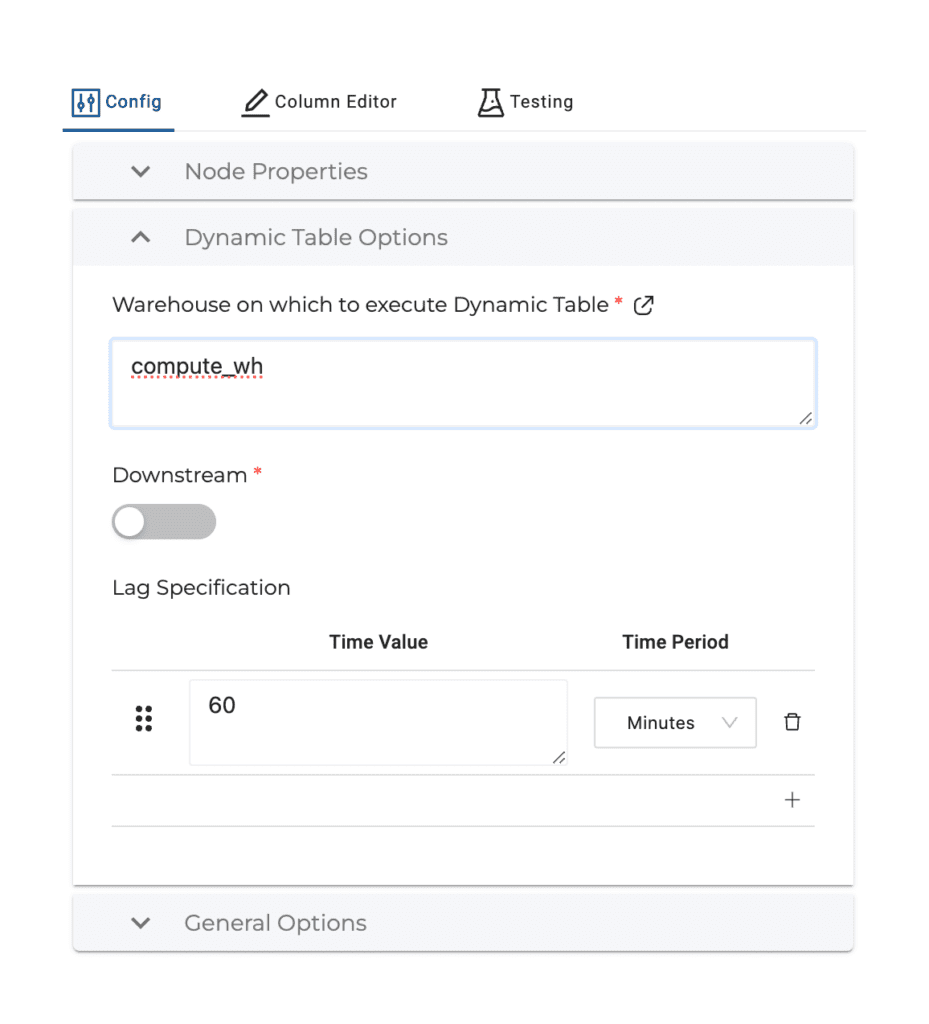
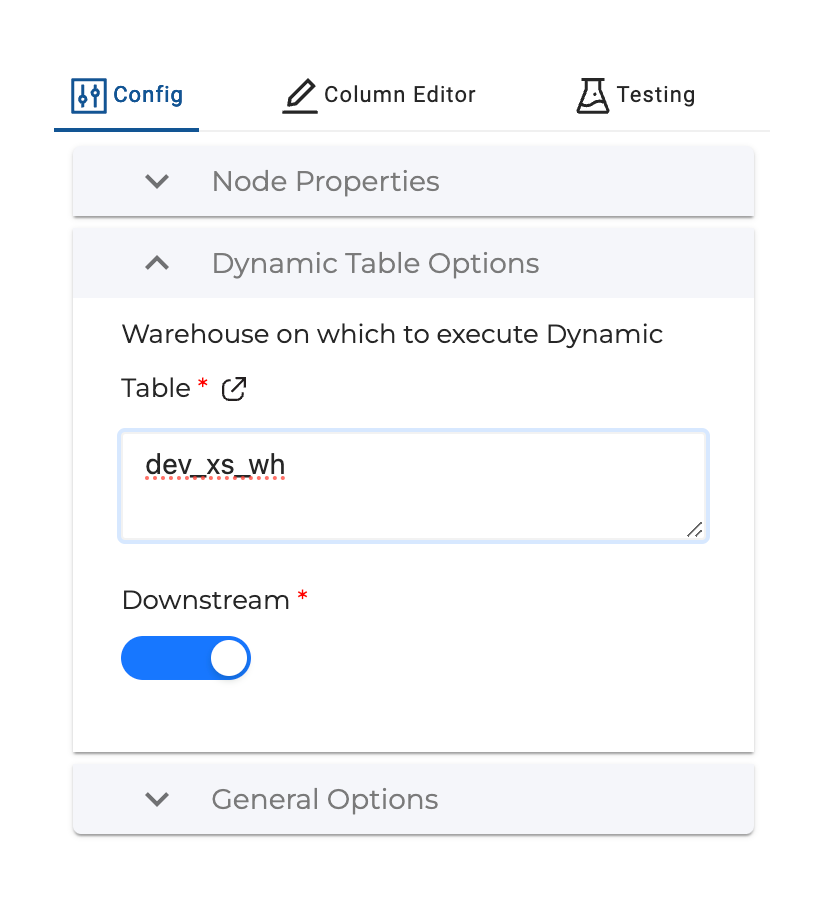
After that we can set the Dynamic Table Options:
Warehouse on which to execute Dynamic Table: Specifies what warehouse the Dynamic Table should use when it refreshes. This can be changed when deploying to an upstream environment.
Downstream: True / False config. If True, the Dynamic Table will refresh based on the Lag Specification of downstream Dynamic Tables. If False, you can set a Lag Specification to refresh the Dynamic Table.
Lag Specification: Visible when Downstream is set to False. Enter lag specification used to refresh the Dynamic Table using Seconds, Minutes, Hours, or Days.
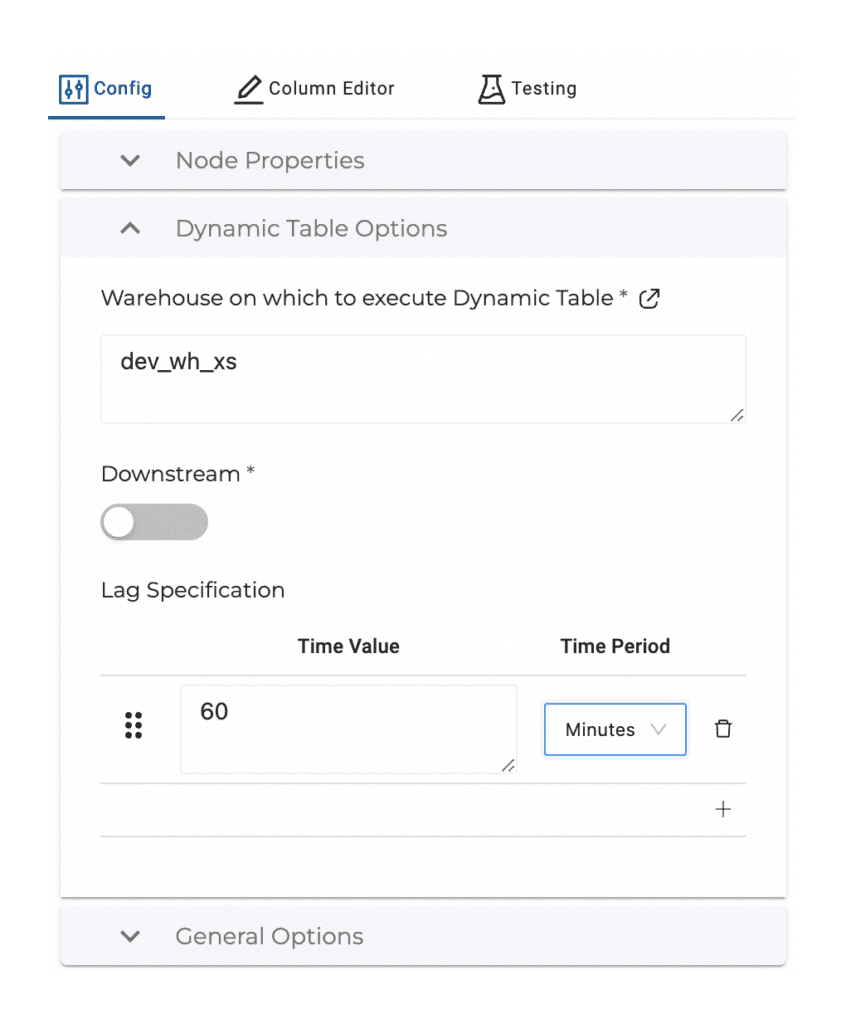
Finally, there are some General Options that can be set if desired:
Distinct: Adds DISTINCT to SELECT statement.
Group By All: Adds GROUP BY ALL to SELECT statement
Distinct and Group By All are mutually exclusive.
Multi Source: Allows you to UNION or UNION ALL multiple sources.
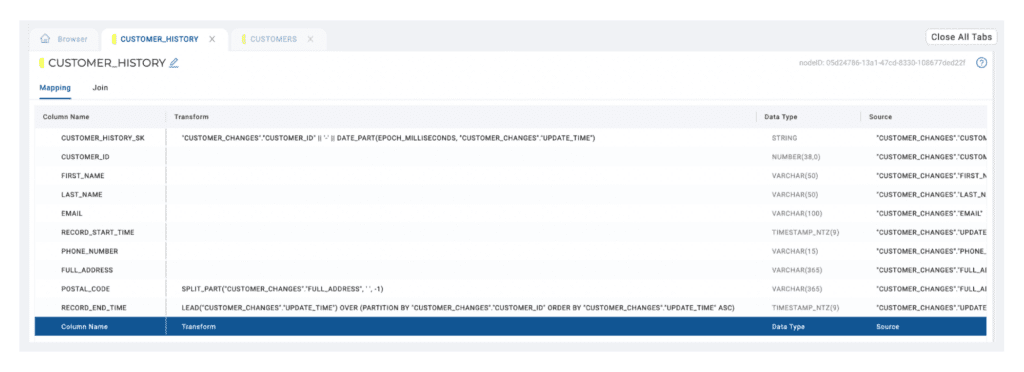
Next, we can modify the Mapping Grid to add the transformations Sasha used to build the Type 2 SCD.
When complete, we can hit the Create button. If there are no errors in the SQL we will see that Coalesce runs two stages:
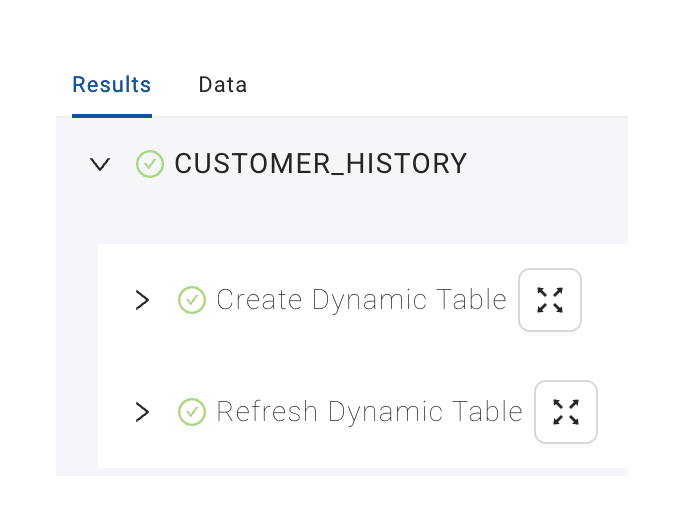
Stage 1 – Create Dynamic Table: This will create the Dynamic Table in Snowflake based on the configuration of the node.
At this point there is no data in the Dynamic Table and there won’t be until the next refresh, kicked off by either the Downstream node or the Lag specification.
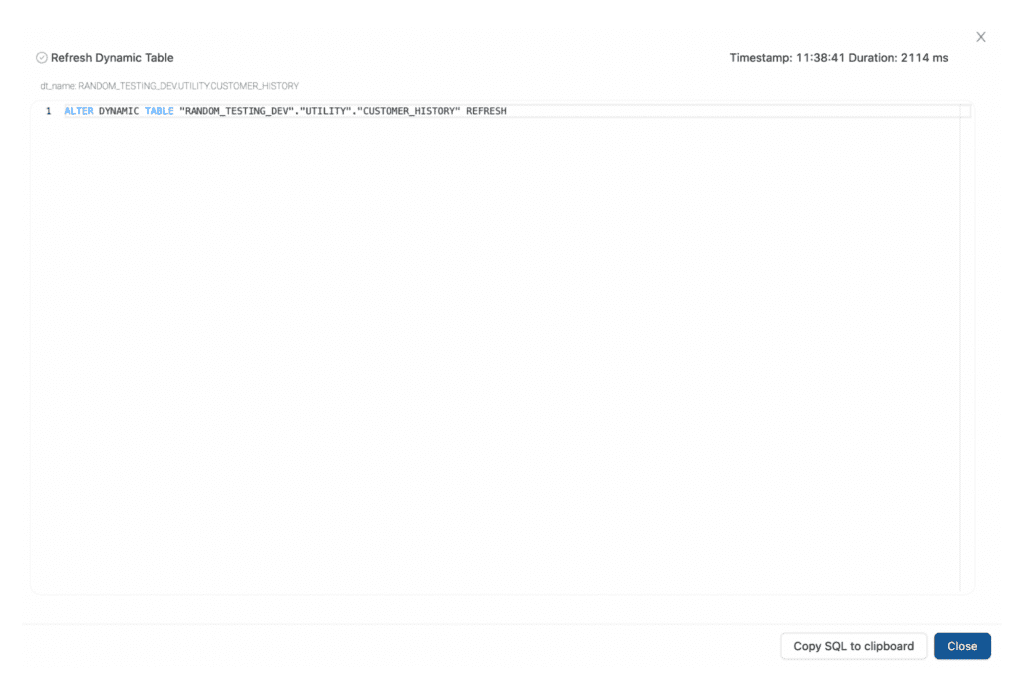
To make data immediately available in the Dynamic Table, we refresh immediately after it is created.
Stage 2 – Refresh Dynamic Table: This stage will run ALTER DYNAMIC TABLE … REFRESH so we have immediate data availability.
Looking at the SQL statements for each stage, we see that they are slightly different than what Sasha had created by the data matches.
Stage 1 – SQL
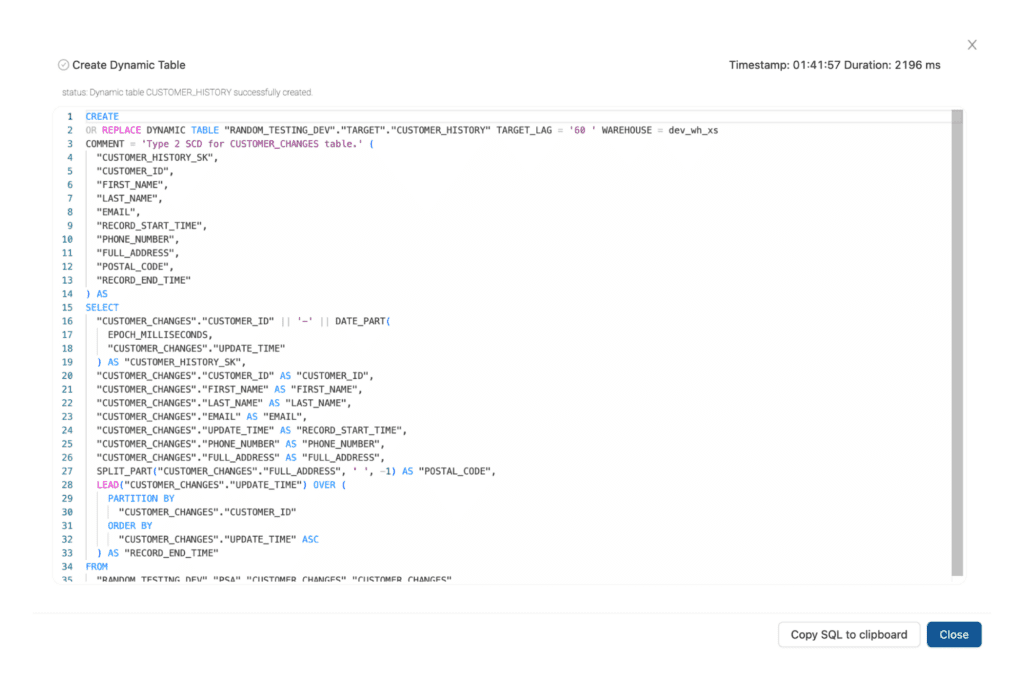
Notice that TARGET_LAG and WAREHOUSE have been set according to our configurations.
Stage 2 – SQL
Dynamic Table Data

Customers Table
To create the CUSTOMERS Dynamic Table with current records for each customer, I’ll add another Dynamic Table Stage node:
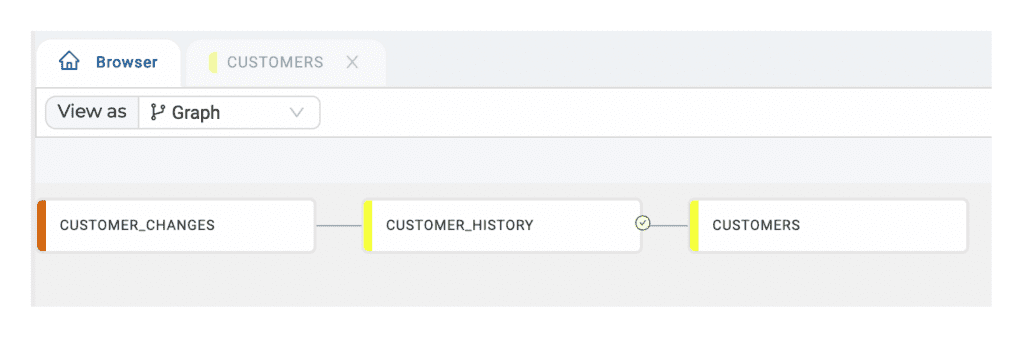
Next we’ll set a Warehouse and Lag in the node configurations:
And include a filter on “CUSTOMER_HISTORY”.”RECORD_END_TIME” IS NULL.
This will show only current values for each CUSTOMER_ID.
Downstream Option
Finally, we can make use of the Dynamic Table Downstream option by going back to the CUSTOMER_HISTORY node and changing the configuration.
Changing to downstream means the CUSTOMER_HISTORY Dynamic Table will refresh based on the schedule of the CUSTOMERS Dynamic Table.
Dynamic Table Dimension
We can make this even easier by customizing the Dynamic Table Stage node and automating the SQL generated for Dimension Specific Columns.
Utilizing the same setup as before, this time I’m going to add a Dynamic Table Dimension node to the Workspace.
In this node, a new Configuration Group has been added for Dimension Options.
There are two Dimension Options to select, both of which are Column Selector configs.
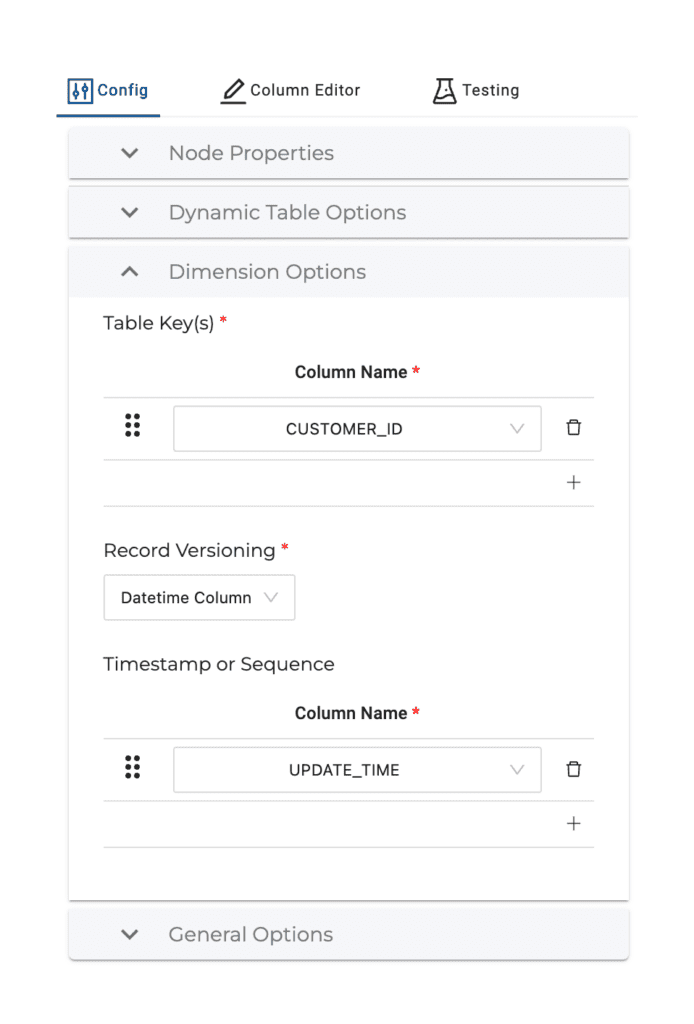
Table Key(s) – One or more columns that uniquely identify rows coming in from the source.
Record Versioning – One or two columns that identify when a record was created in relation to other records with the same Table Key. This could be a Datetime column, combination Date Column and Time Column or Numeric Column, maybe a sequence.
In our case we’ll select CUSTOMER_ID for Table Key and UPDATE_TIME for Record Versioning.
Looking at the Mapping Grid, we see System Columns have been added prepopulated with column transforms that reference Coalesce Macros.
These macros use the selections made in the Dimension Options configs to generate the SQL the node is ultimately creating.
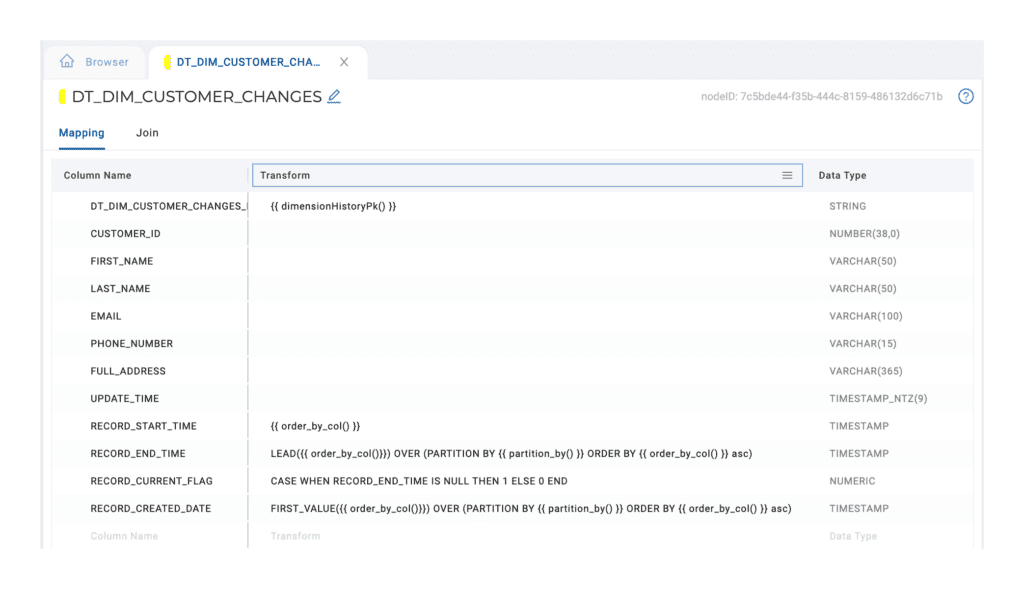
For example, the macro dimensionHistoryPK calls the following Macro when Coalesce renders the node.

I’m going to delete the UPDATE_TIME column since it is equivalent to RECORD_START_TIME and then hit the Create button.
We run the same stages as the Dynamic Table Stage node:
The Refresh Dynamic Table stage is the same as before, but the SQL generated in the Create Dynamic Table stage is now specific to the dimension logic created by Sasha. I actually added a new System Column for RECORD_CREATE_DATE that shows the value of the first instance a row was created for a specific CUSTOMER_ID using the FIRST_VALUE function.
The beauty of using the Dynamic Table Dimension node is that we didn’t have to write any of the more complex SQL. It was already templated in the node type!

Conclusion
With Dynamic Tables, Snowflake has added a powerful tool to the toolkit. Coalesce makes them even easier to create, use and manage at scale!
If you would like to try the new Dynamic Table Stage node, file a support ticket with Coalesce and it will be added to your Org ready to use.