The most efficient data processing for a data warehouse is often achieved by processing the least amount of data possible. Incremental processing strategies are used to reduce the amount of data processed during each batch by only processing data once, and excluding already processed data. This enables teams to not only process data faster, but also results in significantly lower compute costs.
Let’s take a look at the most efficient incremental processing strategies and the pros and cons of each approach.
Why Apply Incremental Processing
The goal of data processing in a data warehouse is to take raw operational data and reformat that data into a design optimized for consumption by BI tools and data science projects. Data engineers need to build processing that applies filters, data rules, business rules, aggregation rules and quality checks. As well as getting the data ready, accurate, and optimized for consumption, the processing should also be optimized for fast, efficient, and reliable execution.
Incremental loading strategies can be applied at several places along the processing pipeline of a data warehouse, for example in the Extract and Load of raw data, during the processing of data marts, and during the processing of an aggregate layer. Each layer could potentially use a different strategy. Typical layers of a data warehouse might include multiple persistent layers – and each process step (the -> in the line below) could employ an incremental strategy.
Processing layers:
- SOURCE -> LAND -> DATA VAULT/STORE -> DATA MART -> AGGREGATES
The goals of an incremental processing strategy are:
- Optimized processing – minimize the time and compute resources needed to update / refresh the data warehouse during normal operations by minimizing the volume of data processed.
- Simple and consistent – easy to understand, fix, and extend. The data warehouse is constantly evolving and the incremental load strategy should be as consistent and easy to use / reuse.
- Self-maintaining – can cope with operational problems such as changed / missed processing schedules without manual intervention. For example, if the scheduler goes down on Friday night and is not discovered till Monday morning, we should be able to restart on Monday morning and have everything fix itself.
- Same code for incremental and full (re)load – we don’t want to maintain two code paths for incremental vs full loads as this duplicates development and testing effort.
Incremental Processing Strategies
The primary options for designing an incremental processing strategy are:
- High Water Mark – efficient and fast. The favored approach when it can be used.
- Key Join – less efficient. Useful only for transactional (immutable) datasets.
- Parameter Based – efficient and fast, but carries more risk.
- Source Batches – inflexible (relies on source loading), but can be efficient. In this system, the source system provides data in batches that are incremental – for example daily extract files from a mainframe. In this case the processing doesn’t have to do much other than process the data provided.
In more detail:
High Water Mark
This approach calculates the maximum value of a last modified date, loaded date or some incrementing value loaded so far (the High Water Mark) and uses this to filter the incoming dataset. The High Water needs to be stored in a target, persistent table (for example a Dimension, Fact, Aggregate or Data Vault table) which can then be queried to identify the maximum value processed and persisted so far.
Coalesce can leverage Snowflake features such as Streams, Dynamic Tables or Hash comparisons to identify changed data if no change timestamp is available in the source data. This gives us the flexibility to efficiently assign an insert or change timestamp that we can use for a High Water Mark.
An example of this High Water Mark approach in Coalesce is the Fivetran Incremental Node type that uses the standard _FIVETRAN_SYNCED column as a High Water Mark column in its code generation. The Coalesce User Defined Node automatically applies a filter that uses this High Water Mark:
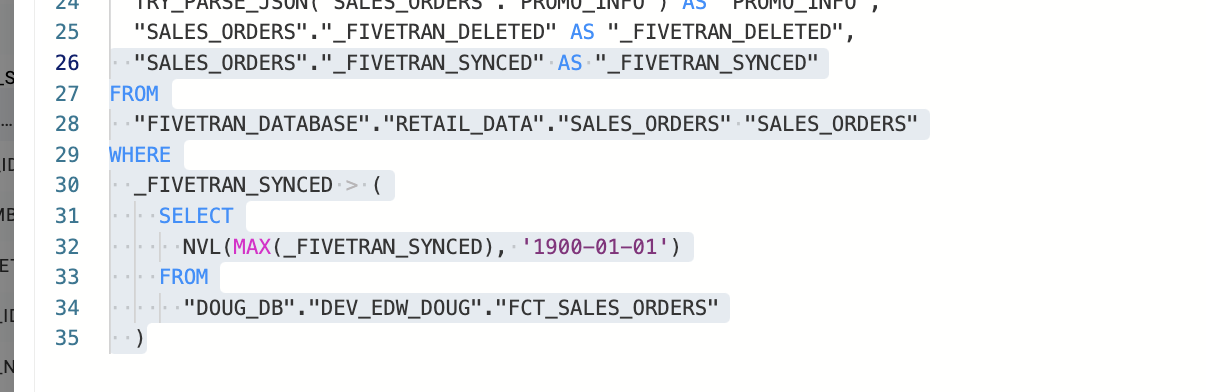
Key Join
Rather than filtering data based on a maximum incrementing High Water Mark – a filter is applied to a unique key – most typically a transactional identifier. This requires a (OUTER) JOIN between the Incoming dataset and the target / persistent table to eliminate transactions that have already been processed and loaded. This solution could JOIN some very large tables together in order to identify the incremental dataset, and for this reason is less efficient than the High Water Mark. For example:

Parameter Based
In this case a parameter is calculated (for example, a date) and passed to processing at run time to control the data processed in a batch with a filter – similar to the High Water Mark. Parameters add some risk to the system because they are calculated separately from the application of the filter. For example, we might calculate the latest date processed so far and store it in a parameter. Then, when we process the incremental data set the parameter is used to filter the data. If there is a problem, partial process or failure between the calculation of the parameter and its use in a filter, the processing could fail or miss data.
Incremental Pipeline Issues
The issues that need to be considered when designing incremental pipelines:
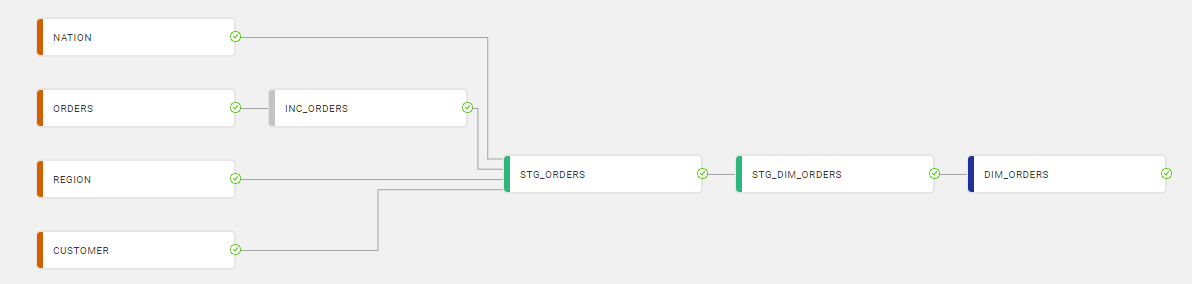
- Joining data together – incrementally loaded / non persistent (flush and fill) tables can not be joined together unless they are synchronized. The incremental loading strategy should be applied to the high volume table and joined to fully populated reference tables. In this example below, the incremental Orders dataset (INC_ORDERS) is joined to full datasets of the lower volume tables: CUSTOMER, NATION and REGION:
- Physical deletes – incremental loading works just fine when data is logically deleted in a source system, because a delete flag is a tracked change to the data. However, physical deletions are a problem because we don’t know whether a record is removed from a data set because it is outside of our incremental filter, or because it is deleted.
A common approach to working with physical deletes and incremental processing is the “SHORT FAT / TALL THIN” approach where the data is processed in two batches. One batch (SHORT FAT) is an incremental dataset containing new / changed data. The second batch processes deletes either by passing a list of deleted keys, or a full set of keys (LONG THIN) to identify deleted data. Only the list of (deleted) Keys is required to identify the deleted records, so no other attributes are required.
Conclusion
The techniques we reviewed can be used to reduce cost and speed up processing on any data platform. Coalesce can help build these patterns into your pipelines and processing to automatically generate and standardize SQL. Want to give it a try? Create a free Coalesce account here, or request a demo.