
Delivering Value with Data Transformations Through Automation is an excerpt from Chapter 3 of the O’Reilly Report “Automating Data Transformations: Enable Your Organization to Solve the Largest Bottleneck in Analytics.”
Co-authored by Armon Petrossian, CEO and Co-Founder of Coalesce, and Satish Jayanthi, CTO and Co-Founder of Coalesce. Published by O’Reilly Media, April 2023.
Principles of Data Value
The concept of providing value with data is not new, though it has grown in popularity and depth in the last few years. We feel data value is best approached through the data mesh framework. When viewed through this lens, it becomes apparent that a decentralized approach will be transformative in the data space. Decentralization of data skill, combined with a column-aware architecture and automation in the transformation layer, will serve to deliver value in the most efficient way possible.
Product-First
In Chapter 1 we introduced the concept of data as a product (DaaP), in which valuable data is easily discovered, understood, trusted, and explored. A product-first mindset means developing data resources with the following characteristics in mind:
Discoverability
How do stakeholders know about that great summary table an analyst built? How can you avoid duplicate queries that return slightly different answers to the same question? Data discoverability reduces the friction to finding the data that already exists and the work that has already been done. While metadata collection is a prerequisite, dissemination of your team’s data universe is key. Without the ability to educate users on what exists in near real time (as assets are created), many efficiency improvements will be overlooked! Be sure to evaluate the discoverability of your data as you invest in data governance and transformation tooling.
Understanding
Establishing understandable data begins with the transformation layer. Solutions that allow for column-level lineage are key as they provide the greatest amount of context. Enforcing rigor in data assets is essential, as it reduces the discipline required to construct consistent outputs: in many data platforms, the responsibility falls on one or a handful of individuals to police code, ensuring that conventions are followed, or to construct complicated CI/CD processes to lint and verify work.
Trust
Building trust in data is an arduous process. It requires a high degree of consistency and a dedication to robust and accurate pipelines. Failures, whether of data jobs or the ability to deliver accurate reporting, will not soon be forgotten. This will undermine even the best attempts to integrate a data-driven culture. Using the modern data stack, trust is acquired through production systems built for uptime and consistency. A rigorous adherence to data as code and documented processes will help to ensure services that inspire trust in the end user.
Exploration
Explorable data empowers stakeholders to quickly find answers to their questions. Becoming comfortable with data systems will enable them to generate new questions and ideas, unlocking the true power of distributed data knowledge and kicking off the virtuous cycle of the scientific method. Data practitioners should seek to implement a framework that enables many members of their team to create data systems that adhere to the preceding four characteristics. This starts with a column-first mindset.
Column-First
In recent years, data observability has become mainstream. At one time it was incredibly complex, but now firms like Atlan, Monte Carlo, and Datafold have helped data teams to better understand lineage, comply with regulation, and even detect silent errors/unintended outputs without the need for DIY tracking systems or anomaly detection services.
What drives data observability? Understanding is not possible without scrutiny at the finest grain possible—the column level. By recognizing how each column is transformed and where these columns go, a wealth of functionality abounds. Unfortunately, observability and transformation have evolved separately in the MDS, though the two are inexorably linked. While the aforementioned tools work well, they’re separate from the source of data changes: the transformation layer.
Additionally, current code- and GUI-first transformation solutions are built at the table level. To understand columnar data, one has to purchase, implement, and maintain a separate observability service. This is inherently inefficient, as many of these operate via reverse engineering that attempts to circumvent table-level shortcomings in the transformation layer.
The current, circuitous approach is disjointed: every column in a data warehouse is sourced from a raw table that’s created through ingestion. From ingestion, these columns are transformed to the tables and views used for decision making (see Figure 3-1).
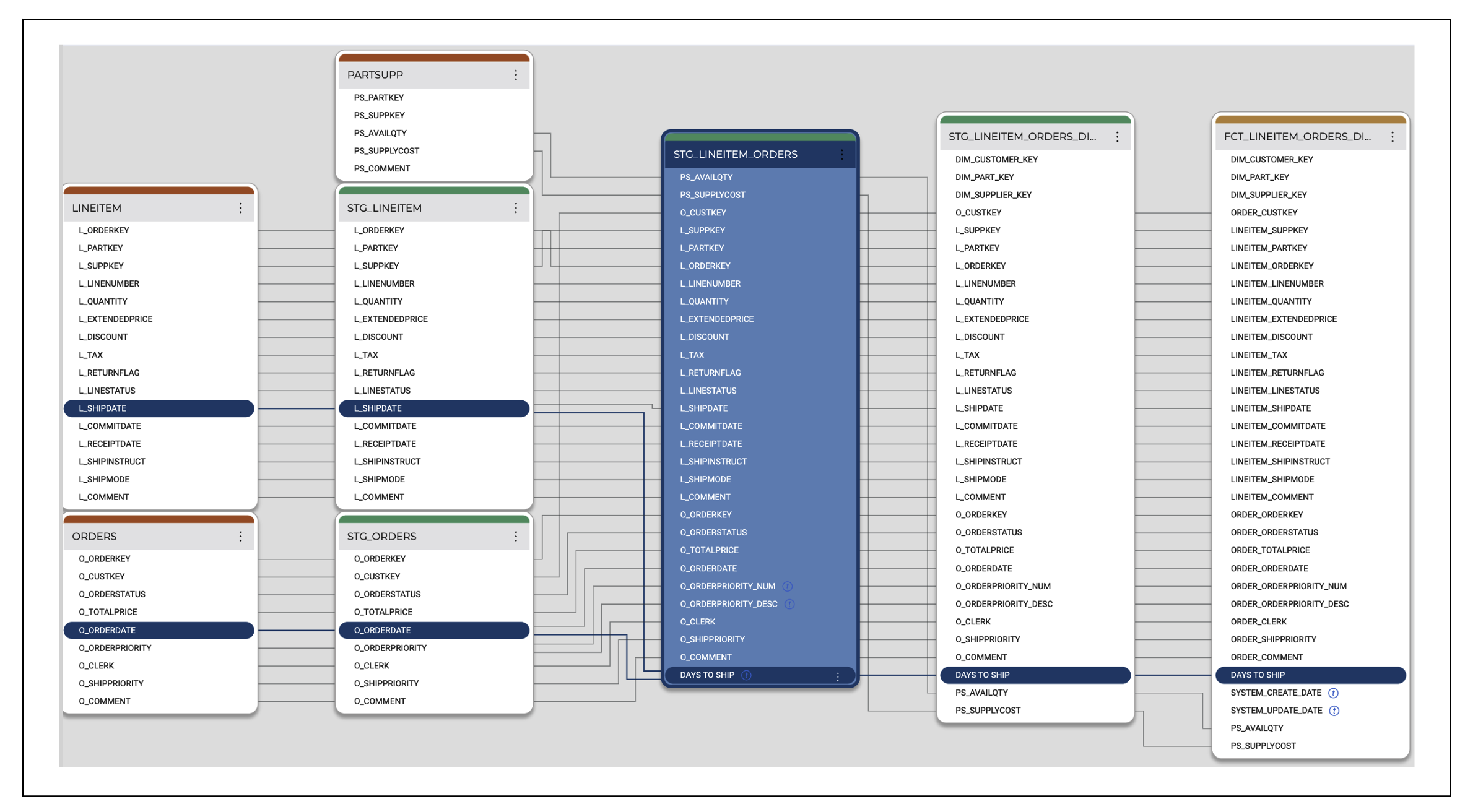
Figure 3-1. Column-level lineage is the most visual benefit of a column-aware architecture
Thus, if you track metadata at the column level, starting from your entry point and interwoven with your transformation tool, it should be possible to tie each column directly back to the source. It follows that this should take place in the transformation layer, not a separate solution that tries to back in to observability. The benefits of a column-based architecture go far beyond metadata management: the ability to craft and distribute the building blocks of data transformation at scale is made possible only through column awareness.
It’s our belief that the transformation platform that delivers the most value will be one founded on a column-first approach, not only with hybrid code and GUI implementation but also by being built on the foundations of data transparency and observability. Value in data transformation starts at the column level. At the finest grain possible, you can leverage the true power of automated transformation, enhancing the discoverability, understanding, trust, and exploration of our datasets and delivering value with the MDS.
Optimizing the Transformation Layer
The concepts of data mesh and DAaaS/DaaP revolve around a decentralized structure for data curation. The ultimate goal is to enable every team to build relevant data infrastructure. It might sound trivial for a small company, but this approach becomes critical as the company grows.
Read the rest of this chapter – and the full report, Automating Data Transformations: Enable Your Organization to Solve the Largest Bottleneck in Analytics; published by O’Reilly Media, April 2023.